Synchronization¶
基本搬运的是 V1CeVersa 的内容。
竞争条件:多个进程并发访问和操作同一数据并且执行结果与特定访问顺序有关
为了防止竞争条件,需要确保一次只有一个进程可以操作变量 count,为了实现这个目的,我们需要进程按照一定方式进行同步。
解决临界区问题的方法必须满足下面三条要求:
- Mutual Exclusion/互斥访问:在同一时刻,只有一个进程可以执行临界区(critical section 只能有一个进程在跑);
- Progress/空闲让进:当没有线程在执行临界区代码时,必须在申请进入临界区的线程中选择一个线程,允许其执行临界区代码,保证程序执行的进展;
- Bounded Waiting/有限等待:当一个进程申请进入临界区后,必须在有限的时间内获得许可并进入临界区,不能无限等待。
Peterson's Method¶
Peterson 解决方案适用于两个进程交替执行临界区与剩余区。
两个进程共享两个数据项:int turn; bool flag[2];
while(true){
flag[i]=true;
turn=j;
while(flag[j]&&turn==j);
/*critical section */
flag[i]=false;
/*remainder section (一般是用于释放进程)*/
}
但是对于现代的计算机,指令可能会被重新排序,例如:
线程一执行:while(!flag); print x;
线程二执行:x = 100; flag = true;
对于线程二,可能会先执行 flag = true,导致出现错误。
硬件同步支持¶
内存屏障¶
- 内存模型:计算机体系结构如何确定它向应用程序提供哪些内存保证。
- 强排序:一个处理器的内存修改对其他处理器立即可见
- 弱排序:内存修改可能不会立即背其他处理器看到
- 内存屏障:强制将内存中任何修改传播到其他处理器的指令,当执行内存屏障指令时,系统确保在执行任何后续加载/存储前,先完成现在的加载和存储(相当于在这里打了个标记,我之前和我之后不能交换)
硬件指令¶
很多现代操作系统提供特殊硬件指令,用于检测和修改字的内容,或者作为不可中断的指令(原子/Atomically/Uninterruptably) 地交换两个字,我们可以通过使用这些特殊指令,相对简单地解决临界区问题。
原子操作的定义¶
- 原子操作是指在执行过程中不会被中断的操作。
- 在多线程环境中,原子操作可以确保一个线程在执行该操作时,其他线程无法同时访问或修改同一资源。
相当于,系统正常并行线程的时候,会把线程的指令打散执行,但是原子操作是不会被打散的。
这里使用指令 test_and_set() 和 compare_and_swap() 抽象了这些指令背后的主要概念。
test_and_set()¶
本质上就是返回 target 的值,并将其修改成 true.
利用 test_and_set() 来实现互斥:
do {
// Entry section
while (test_and_set(&lock))
; // Do nothing
// Critical section
// Exit section
lock = false;
// Remainder section
} while (true);
倘若某个时刻 lock 为 false,很可能有不止一个线程调用了 test_and_set(),但是由于 test_and_set() 是原子的,所以只可能有一个线程返回 false。
但是 test_and_set() 并不能确保有限等待,下面就是一个例子:
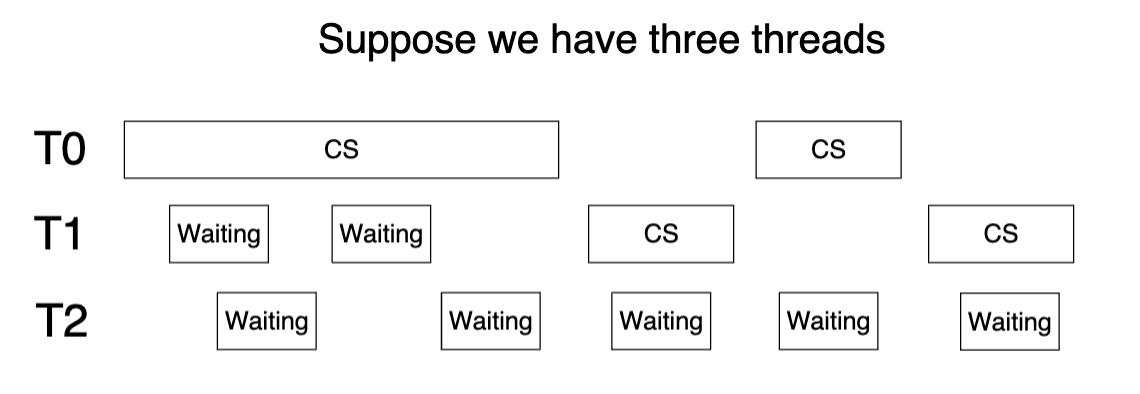
谁也不知道 T2 会等到哪里去(这取决于调度),我们可以这样修改代码,这里共用的数据结构是 bool waiting[n] 和 int lock:
do {
waiting[i] = true;
while (waiting[i] && test_and_set(&lock)) ;
waiting[i] = false;
// Critical section
// Exit section
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = false;
else
waiting[j] = false;
// Remainder section
} while (true);
我们首先将 waiting[i] 置为 true,然后检查 lock,如果 waiting[i] 被释放或者 lock 为 false,那么就进入临界区,同时上锁(第 3 行)。在退出临界区的时候,我们向下检查后面的线程,寻找下一个正在等待的线程(第 8 到 10 行),若是没有找到(j == i),那么就释放锁,这是因为没有线程在等待(第 11 行和第 12 行);否则,就将 waiting[j] 置为 false,释放该线程,继续循环,让其进入临界区(第 14 行)。
copare_and_swap()¶
compare_and_swap() 也是以原子的方式对两个字进行操作,但是是使用基于交换两个字的内容的机制:
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}
只有当 *value 的值等于 expected 的时候,才会将 *value 设置为 new_value,并且返回 *value 的原始值。
互斥的实现也是类似的,但是这里 compare_and_swap(&lock, 0, 1) 和 test_and_set(&lock) 的逻辑是反的,需要注意一下,但是两条指令并没有本质区别。
加上有限等待的实现,这里共用的数据结构是 bool waiting[n] 和 int lock:
while (true) {
waiting[i] = true;
key = 1;
while (waiting[i] && key == 1)
key = compare_and_swap(&lock, 0, 1);
waiting[i] = false;
// Critical section
// Exit section
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = 0;
else
waiting[j] = false;
// Remainder section
}
x86 实现了 cmpxchg 这个指令,可以实现 compare_and_swap() 的功能,为了强制执行原子执行,可以使用 lock 前缀,使得在目标操作数更新的时候锁定总线。汇编的一般形式是 lock cmpxchg <destination operand>, <source operand>。ARM 也有类似的指令。
原子变量¶
通常,指令 compare_and_swap() 并不直接用来实现互斥,而是作为实现别的工具的基本构建块。例如我们用这个指令,搭建一个原子变量,对于这个变量的操作都是原子的。
有界缓冲区问题可以通过实现对整型变量的原子递增递减来解决(不然两个线程可能会操作同样的寄存器):
void increment(atomic_int *v) {
int temp;
do {
temp = *v;
} while (temp != compare_and_swap(v, temp, temp + 1));
}
互斥锁(Mutex Locks)¶
最简单的高层软件工具就是互斥锁/Mutex Locks,我们使用互斥锁保护临界区并且防止竞争条件。一个进程在进入临界区之前必须申请/Acquire锁,退出临界区的时候必须释放/Release锁。
每个互斥锁都有一个布尔变量 available,这个值表明这个锁是否可用,如果锁可用,调用 acquire() 就会成功,并将 available 设置为 false。如果一个进程尝试获取不可用的锁,那么这个进程就会被阻塞,直到锁可用。
另外,我们要求调用 acquire() 和 release() 都必须是原子的,这一般通过硬件的原子指令来实现,我们将使用 compare_and_swap() 来实现这两个函数。
void acquire() {
while (compare_and_swap(&available, 1, 0) != 1)
// equal to compare_and_swap(&available, 0, 1)
; // Do nothing, busy waiting
}
void acquire_naive() { // not atom
while (available == 0)
; // Do nothing, busy waiting
available = 0;
}
void release() {
available = 0;
}
我们通过这样的 acquire() 和 release() 函数实现的锁也被称为自旋锁/Spinlock,因为进程在等待锁可用的时候会一直自旋。
但是这里有一个问题,就是忙等待/Busy Waiting.
Busy Waiting 的时间是进程从申请锁到释放锁的时间。当有一个进程在临界区的时候,任何其他进程在进入临界区的时候必须要连续循环调用 acquire()。
考虑有 N 个线程使用一个 CPU 的情况:只有一个线程可以进入临界区,其他 N - 1 个线程即使被分配到了 CPU,但都在自旋等待,这样会浪费大约 N-1/N 的 CPU 时间。
在保持互斥锁的结构不变的情况下,我们可以减少忙等待,只需要让别的等待的线程释放 CPU 就好了:
实现方法:添加一个队列,当别的线程发现锁是不可用的时候,将这个线程的进程状态调到 SLEEP,将其加到这个队列中,并且调用 schedule() 函数。
当锁定时间很短的时候,自旋锁是多处理器系统锁定机制的首选。
锁要么是争用的/Contended,要么是非争用的/Uncontended。如果线程在尝试获取锁的时候被阻塞,那么认为这个锁是争用的;如果线程在尝试获取锁的时候有可用锁,那么认为这个锁是非争用的。争用锁可以遇到高争用/High Contention(相对大量的线程尝试获取锁)或者低争用/Low Contention(尝试获取锁的线程很少)。一般高争用的锁会降低并发程序的整体性能。
信号量/Semaphores¶
定义¶
互斥锁被认为是最简单的同步工具,信号量提供了一种更复杂/强大的同步工具。信号量/Semaphore 包含着一个整型变量,除了初始化之外,这个整型变量只可以被两个原子操作 wait() 和 signal() 访问。
- 二进制信号量/Binary Semaphores:只能取 0 或 1 的信号量,类似于互斥锁。
- 计数信号量/Counting Semaphores:可以取任意非负整数的信号量。
本质上,信号量的初始值可以视作可用资源的数量,wait() 和 signal() 分别用于申请和释放资源。
这样的信号量其实也具有忙等待的问题,我们可以通过这样的想法来修改 wait() 和 signal() 的定义,让它从忙等待变成阻塞。
typedef struct {
int value;
struct process *wating_queue;
} semaphore;
void wait (semaphore *s) {
s->value--;
if (s->value < 0) {
add_to_list(s->wating_queue, current_process);
block();
}
}
void signal (semaphore *s) {
s->value++;
if (s->value <= 0) {
process *p = remove_from_list(s->wating_queue);
wakeup(p);
}
}
- 这样可以保证仅有极少的进程在 Busy Waiting.
课上的例子
typedef struct __lock_t {
int flag; // i.e. value
int guard; // i.e. spinlock
queue_t *q;
} lock_t;
void lock_init(lock_t *m) {
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; // Acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1;
m->guard = 0; // release the spinlock
} else {
queue_add(m->q, gettid());
m->guard = 0;
park(); // Block until awaken and park() is schedule() indeed
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; // Acquire guard lock by spinning
if (queue_empty(m->q))
m->flag = 0;
else
unpark(queue_remove(m->q));
m->guard = 0;
}
简单解释一下这段代码实现的锁的功能:
guard其实是一个互斥锁,用来保护flag的访问,若是其为 1 表示当前互斥锁没被占用,允许进程访问flag,同时访问的时候会将guard设置为1,防止其他进程访问flag;flag为 0 表示锁是可用的。当一个进程调用lock()的时候,若通过互斥锁且发现flag为 0,就将flag设置为 1,释放互斥锁,lock()返回,进程进入临界区;若是flag为 1,就将进程加入等待队列,然后调用park(),进程被阻塞,安心睡去。- 若是一个进程完成临界区的执行,调用
unlock(),如果队列为空,那么就将flag设置为 0,期待下一个进程调用lock(),释放互斥锁,unlock()返回使用锁;如果队列不为空,那么就将队列中的一个进程唤醒,然后操作互斥锁 。
这个程序的 21 行和 22 行不能互换,倘若互换了,就会出现下面的情况:某个进程执行到 park(),被调度后安心 sleep(),但是这时互斥锁 guard 还是 1,其他进程就一直会停在第 14 行,这样持锁 sleep,就也会出现 Infinite Blocking。
另外,当临界区(waiting list)长度较短的时候,使用互斥锁比使用信号量更佳高效。具体而言,当临界区的长度小于线程切换的消耗时,临界区长度一定就是短的,这时候使用互斥锁更好。
饥饿与死锁¶
- 饥饿/Starvation:一个或多个进程无法获得所需的资源,导致无法继续执行。
- 死锁/Deadlock:两个或多个进程无法继续执行,因为每个进程都在等待另一个进程释放资源。
优先级反转/Priority Inversion¶
考虑有三个优先级不同的进程 P_H、P_M 和 P_L,P_M 持有资源 R,P_H 和 P_L 都在等待 R。这时候哪个进程都没法执行:虽然 P_H 优先级最高,但是由于 P_M 持有 R,P_H 会被阻塞,需要一直等待锁;P_L 当然是不配拥有 R 的,因为其优先级最低,需要等待 P_M 释放 R 且 P_H 执行完;P_M 也不能执行,因为其优先级在 P_H 和 P_L 之间,轮不到它拥有 CPU,因此一直不能释放 R。
这就产生了优先级反转:一个高优先级的进程间接地被一个低优先级的进程抢占。解决方法是优先级继承/Priority Inheritance:当一个低优先级的进程持有一个高优先级的进程需要的资源的时候,操作系统会将低优先级的进程的优先级提升到高优先级的进程的优先级,直到低优先级的进程释放资源。
经典同步案例¶
Bounded-Buffer Problem¶
两个进程,一个是生产者/Producer,另一个是消费者/Consumer,它们共享 n 个缓冲区,生产者生成数据并且放进缓冲区,消费者通过从缓冲区取出数据使用数据。我们的目标是保证生产者不会向满的缓冲区中放数据,消费者不会从空的缓冲区中取数据。
- 定义信号量
mutex并将其初始化为 1,这是为了保护对缓冲区的原子访问; - 定义信号量
full_slots并将其初始化为 0; - 定义信号量
empty_slots并将其初始化为 n
Pruducer:
do {
// produce an item
wait(empty_slots);
wait(mutex);
// add the item to the buffer
signal(mutex);
signal(full_slots);
} while (true);
Consumer:
do {
wait(full_slots);
wait(mutex);
// remove an item from buffer
signal(mutex);
signal(empty_slots);
} while(true);
Readers-Writers Problem¶
一个数据集被一些并发的进程共同使用,这些进程分为读进程/Readers 和写进程/Writers。读进程只是读取数据,并不更新数据,但是写进程可以读和写。Readers-Writers Problem 的目标是保证:
- 允许多个读进程同时读数据:Shared Access;
- 但是只允许一个写进程访问共享的数据(要么写进程不访问数据,要么只有一个写进程访问数据):Exclusive Access;
- 非抢占式。
- 定义信号量
mutex并将其初始化为 1,这是为了保护对read_count的互斥访问; - 定义信号量
write并将其初始化为 1,这是为了控制写进程的访问; - 定义整型变量
read_count并将其初始化为 0,通过read_count的值来判断有多少进程正在读数据,并且控制写进程的访问
Writer:
Reader:
do {
wait(mutex);
read_count++;
if (read_count == 1) // first reader
wait(write); // block writers
signal(mutex);
// reading data
wait(mutex);
read_count--;
if (read_count == 0) // no reader reads the data
signal(write); // release the lock, let writers
signal(mutex);
} while (true);
- Reader First:我们解决的就是 Reader First 的问题,即读进程优先于写进程。如果当前正在读进程,那么新来的读进程可以直接读取数据,不需要等待;若是有写进程,必须等待所有读进程完成。
- Writer First:如果当前正在读进程,来了一个读进程和一个写进程,那么读进程会被阻塞,写进程等待当前读进程结束以后直接进行。
若是读进程在读数据的时候被中断然后调度了,那该是什么情况?
其实不需要担心这个问题,既然都有读进程开始读数据了,那么就意味着上面的第 5 行已经被执行了,那么后续的写进程就一定会被阻塞/或者被加到信号量 write 的 waiting_queue 中,写进程是 Ready 状态,根本不被调度,而读进程就算被调度也不会影响整个问题的正确性,所以不必担心。
Dining-Philosophers Problem¶
五个哲学家围坐在一张圆桌前,每个哲学家面前有一碗米饭,每两个哲学家之间有一只筷子。哲学家的生活包括思考和进餐,当一个哲学家思考的时候,他不需要任何资源,但是当他饿了的时候,他需要两只筷子才能进餐。问题是如何设计一个协议,使得每个哲学家都能进餐,但是不会发生死锁。
哲学家吃饭问题是一个经典的多资源同步问题。一个朴素的解法是:
vector<semaphore> chopstick(5, 1); // initialize semaphores to all 1
philosopher(int i) {
do {
wait(chopstick[i]);
wait(chopstick[(i + 1) % 5]);
eat();
signal(chopstick[i]);
signal(chopstick[(i + 1) % 5]);
think();
} while (true);
}
但是这个算法会出现死锁的情况:可能某时刻每个人同时拿起左边的筷子。一种直接的方法是:只允许同时拿起两根筷子,也就是轮流询问每个人是否能够拿起两根筷子,如果能则拿起,如果不能则需要等待那些筷子放下。这在上面的第 5 行和第 6 行上下加一个互斥锁就可以了。
另一个巧妙的方法是:让奇数号的哲学家先拿左边的筷子,再拿右边的筷子;让偶数号的哲学家先拿右边的筷子,再拿左边的筷子,这样就不会出现死锁的情况。